1868年,瑞士的内科医生Friedrich Miescher从外科医院包扎伤口的绷带上的脓细胞核中提取到一种富含磷元素的酸性化合物,将其称为核质(nuclein);后来他又从鲭鱼精子中分离出类似的物质,并指出它是由一种碱性蛋白质与一种酸性物质组成的,此酸性物质即是现在所知的核酸(nucleic acid)。1944年Oswald Avery,Colin Macleod和Maclyn McCarty发现,一种有夹膜、具致病性的肺炎球菌中提取的核酸桪NA(deoxyribonucleic acid,脱氧核糖核酸),可使另一种无夹膜,不具致病性的肺炎球菌的遗传性状发生改变,转变为有夹膜,具致病性的肺炎球菌,且转化率与DNA纯度呈正相关,若将DNA预先用DNA酶降解,转化就不发生。该项实验彻底纠正了蛋白质携带遗传信息这一错误认识,确立了核酸是遗传物质的重要地位;DNA遗传作用的进一步肯定来自Alfred Hershey和Martha Chase对一个感染大肠杆菌的病毒的研究。即用放谢性同位素32P标记噬菌体DNA,35S标记其蛋白质外壳,再用标记的噬菌体去感染培养的大肠杆菌,结果发现进入细菌体内,使细菌生长、繁殖发生变化的是32P标记的DNA,而不是35S标记的蛋白质,并且新繁殖生成的噬菌体不含?35S,只含32P。1953年Watson和Crick创立的DNA双螺旋结构模型,不仅阐明了DNA分子的结构特征,而且提出了DNA作为执行生物遗传功能的分子,从亲代到子代的DNA复制(replication)过程中,遗传信息的传递方式及高度保真性,为遗传学进入分子水平奠定了基础,成为现代分子生物学发展史上最为辉煌的里程碑。后来的研究又发现了另一类核酸桼NA(ribonucleic acid,核糖核酸),RNA在遗传信息的传递中起着重要的作用。从此,核酸研究的进展日新月异,如今,由核酸研究而产生的分子生物学及其基因工程技术已渗透到医药学、农业、化工等领域的各个学科,人类对生命本质的认识进入了一个崭新的天地。
第一节 核酸的化学组成
核酸是生物体内的高分子化合物,包括DNA和RNA两大类。
一、元素组成
组成核酸的元素有C、H、O、N、P等,与蛋白质比较,其组成上有两个特点:一是核酸一般不含元素S,二是核酸中P元素的含量较多并且恒定,约占9~10%。因此,核酸定量测定的经典方法,是以测定P含量来代表核酸量。
二、化学组成与基本单位
核酸经水解可得到很多核苷酸,因此核苷酸是核酸的基本单位。核酸就是由很多单核苷酸聚合形成的多聚核苷酸。核苷酸可被水解产生核苷和磷酸,核苷还可再进一步水解,产生戊糖和含氮碱基(图15-1)。
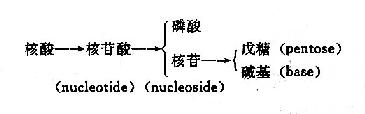
图15-1 核酸的组成
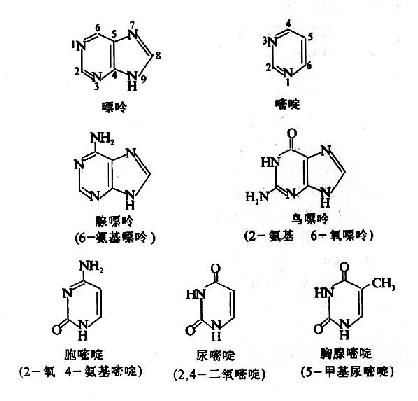
核苷酸中的碱基均为含氮杂环化合物,它们分别属于嘌呤衍生物和嘧啶衍生物。核苷酸中的嘌呤碱(purine)主要是鸟嘌呤(guanine,G)和腺嘌呤(adenine,A),嘧啶碱(pyrimidine)主要是胞嘧啶(cytosine,C)、尿嘧啶(uracil,U)和胸腺嘧啶(thymine,T)。DNA和RNA都含有鸟嘌呤(G)、腺嘌呤(A)和胞嘧啶(C);胸腺嘧啶(T)一般而言只存在于DNA中,不存在于RNA中;而尿嘧啶(U)只存在于RNA中,不存在于DNA中。它们的化学结构请参见图示。
核酸中五种碱基中的酮基和氨基,均位于碱基环中氮原子的邻位,可以发生酮式一烯醇式或氨基?亚氨基之间的结构互变。这种互变异构在基因的突变和生物的进化中具有重要作用。
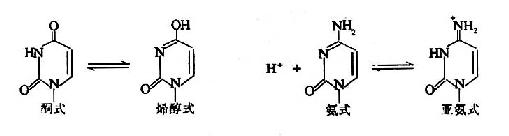
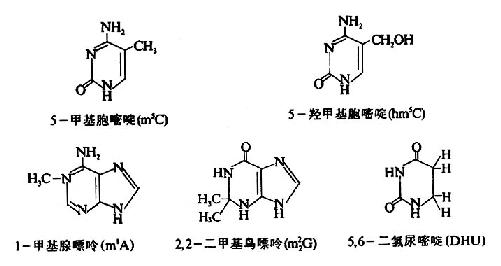
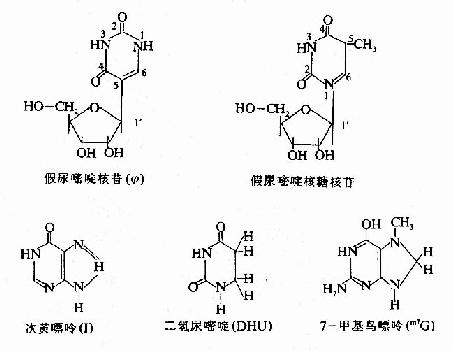
有些核酸中还含有修饰碱基(modifiedcomponent),(或稀有碱基,unusual component),这些碱基大多是在上述嘌呤或嘧啶碱的不同部位甲基化(methylation)或进行其它的化学修饰而形成的衍生物。一般这些碱基在核酸中的含量稀少,在各种类型核酸中的分布也不均一。DNA中的修饰碱基主要见于噬菌体DNA,如5-甲基胞嘧啶(m5C),5-羟甲基胞嘧啶hm5C;RNA中以tRNA含修饰碱基最多,如1-甲基腺嘌呤(m1A),2,2一二甲基鸟嘌呤(m22G)和5,6-二氢尿嘧啶(DHU)等。
嘌呤和嘧啶环中含有共轭双键,对260nm左右波长的紫外光有较强的吸收。碱基的这一特性常被用来对碱基、核苷、核苷酸和核酸进行定性和定量分析。
核酸中的戊糖有核糖(ribose)和脱氧核糖(deoxyribose)两种,分别存在于核糖核苷酸和脱氧核糖核苷酸中。为了与碱基标号相区别,通常将戊糖的C原子编号都加上“′”,如C1′表示糖的第一位碳原子。
戊糖与嘧啶或嘌呤碱以糖苷键连接就称为核苷,通常是戊糖的C1′与嘧啶碱的N1或嘌呤碱的N9相连接。
核苷中戊糖的羟基与磷酸以磷酸酯键连接而成为核苷酸。生物体内的核苷酸大多数是核糖或脱氧核糖的C5′上羟基被磷酸酯化,形成5′核苷酸。核苷酸在5′进一步磷酸化即生成二磷酸核苷和三磷酸核苷。以核糖腺苷酸为例,除AMP外,还有二磷酸腺苷(ADP,adenosine 5′-diphosphate)和三磷酸腺苷(ATP,adenosine 5′-triphosphate)两种形式。核苷酸的二磷酸酯和三磷酸酯多为核苷酸有关代谢的中间产物或者酶活性和代谢的调节物质,以及作为核苷酸有关代谢的中间产物或者酶活性和代谢的调节物质,以及作为生理储能和供能的重要形式。
核苷酸还有环化的形式。它们主要是3′,5′-环化腺苷酸(cAMP,adenosine 3′,5′-cyclicmonophosphate)和3′,5′-环化鸟苷酸(cGMP,guanosine 3′,5′-cyclic monophosphate),化学结构如下。环化核苷酸在细胞内代谢的调节和跨细胞膜信号中起着十分重要的作用。
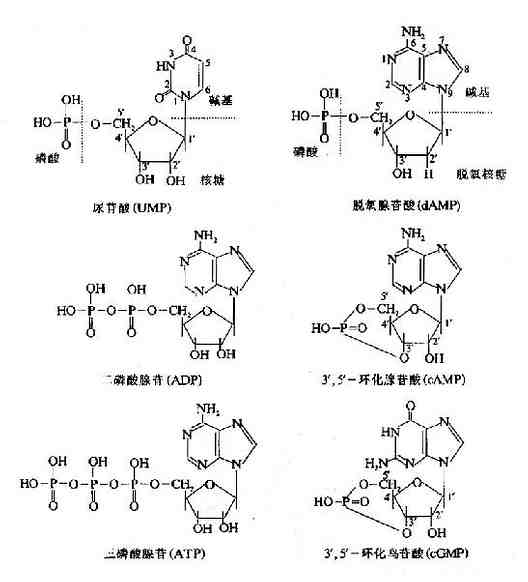
表15-1 核苷酸及相应的核苷、碱基名称中英文对照表
| 核苷酸 |
核苷 |
碱基 |
| 腺苷酸(AMP) |
腺苷 |
腺嘌呤(A) |
| adenosine monophosphate |
adenosine |
adenine |
| 脱氧腺苷酸(dAMP) |
脱氧腺苷 |
|
| deoxydenosine monophosphate |
deoxyadenosine |
|
| 鸟苷酸(GMP) |
鸟苷 |
鸟嘌呤(G) |
| guanosine monophosphate |
guanosine |
guanine |
| 脱氧鸟苷酸(dGMP) |
脱氧鸟苷 |
|
| deoxyguanosine monophosphate |
deoxyguanosine |
|
| 胞苷酸(CMP) |
胞苷 |
胞嘧啶(C) |
| cytidine monophosphate |
cytidine |
cytosine |
| 胞氧胞苷酸(dCMP) |
脱氧胞苷 |
|
| deoxycytidine monophosphate |
deoxycytidine |
|
| 胸苷酸(TMP/dTMP) |
胸苷 |
胸腺嘧啶(T) |
| thymidine monophate |
thymidine |
thymine |
| 尿苷酸(UMP) |
尿苷 |
尿嘧啶(U) |
| uridine monophosphate |
uridine |
uracil |
第二节 DNA的一级结构与功能
(一)DNA的一级结构
核酸是由很多单核苷酸聚合形成的多聚核苷酸(polynucleotide),DNA的一级结构即是指四种核苷酸(dAMP、dCMP、dGMP、dTMP)按照一定的排列顺序,通过磷酸二酯键连接形成的多核苷酸,由于核苷酸之间的差异仅仅是碱基的不同,故又可称为碱基顺序。核苷酸之间的连接方式是:一个核苷酸的5′位磷酸与下一位核苷酸的3′-OH形成3′,5′磷酸二酯键,构成不分支的线性大分子,其中磷酸基和戊糖基构成DNA链的骨架,可变部分是碱基排列顺序。核酸是有方向性的分子,即核苷酸的戊糖基的5′位不再与其它核苷酸相连的5′末端,以及核苷酸的戊糖基3′位不再连有其它核苷酸的3′末端,两个末端并不相同,生物学特性也有差异。
寡核苷酸(oligonucleotide)是指二至十个甚至更多个核苷酸残基以磷酸二酯键连接而成的线性多核苷酸片段。目前多由仪器自动合成而用作DNA合成的引物(Primer)、基因探针(probe)等,在现代分子生物学研究中具有广泛的用途。
表示一个核酸分子结构的方法由繁至简有许多种(图15-2)。由于核酸分子结构除了两端和碱基排列顺序不同外,其它的均相同。因此,在核酸分子结构的简式表示方法中,仅须注明一个核酸分子的哪一端是5′末端,哪一端是3′末端,末端有无磷酸基,以及核酸分子中的碱基顺序即可。如未特别注明5′和3′末端,一般约定,碱基序列的书写是由左向右书写,左侧是5′末端,右侧为3′末端。
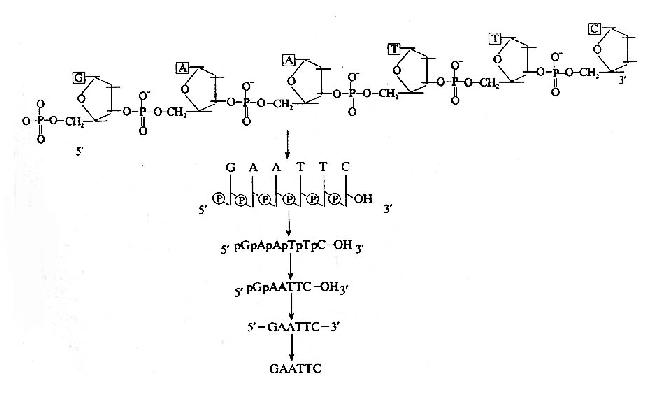
图15-2 核酸分子结构的表示方式
(二)基因组DNA
自然界绝大多数生物体的遗传信息贮存在DNA的核苷酸排列顺序中。DNA是巨大的生物高分子,一般将细胞内遗传信息的携带者枣染色体所包含的DNA总体称为基因组(genome)。同一物种的基因组DNA含量总是恒定的,不同物种间基因组大小和复杂程度则差异极大,一般讲,进化程度越高的生物体其基因组构成越大、越复杂,见(表15-2)。
表15-2 某些有代表性的生物体内DNA大小
|
|
分子量 |
碱基对(bp) |
千碱基对(kb) |
| 最简单的微生物 |
SV40病毒 |
3×106 |
5×103 |
5 |
|
λ噬菌体 |
3.4×107 |
5×104 |
50 |
| 细菌 |
大肠杆菌 |
2.2×109 |
4.6×106 |
4600 |
| 哺乳动物 |
小鼠 |
1.5×1012 |
2.3×109 |
230万 |
|
人 |
1.8×1012 |
2.8×109 |
280万 |
DNA分子中不同排列顺序的DNA区段构成特定的功能单位,即基因(gene)。基因的功能取决于DNA的一级结构。一个DNA分子能携带多少基因呢?如果以1000~1500bp编码一个基因计算,猿猴病毒SV40基因组DNA有5000碱基对(base pair,bp),可编码5种基因,人类基因组含3×109bp DNA,理论上可编码200万以上的基因,然而,由于哺乳动物的基因含有内含子(intorn),因而每个基因可长达5000~8000bp,少数可达20,000bp。按这样大小的基因进行推算,人类基因组相当于40~60万个基因。这可能吗?虽然现在还不知道确切数字,但利用核酸杂交已测得哺乳类细胞含50,000~100,000种mRNA,由此推论整个基因组所含基因不会超过10万个,只占全部基因组的6%,另外5~10%为rRNA等重复基因,其余80~90%属于非编码区,没有直接的遗传学功能。DNA的复性动力学研究发现这些非编码区往往都是一些大量的重复序列,这些重复序列或集中成簇,或分散在基因之间,可能在DNA复制、调控中具有重要意义,并与生物进化、种族特异性有关。可见原核细胞由于DNA分子较小,必须充分利用有限的核苷酸序列,这是真核基因组与原核基因组显然不同之处。
真核基因组与原核基因组在结构上还有很多不同的特点,归纳如下:
1.真核生物基因组结构特点
①真核生物基因组DNA与蛋白质结合形成染色体,储存于细胞核内,除配子细胞外,体细胞内的基因组是双份的(即双倍体,diploid),即有两份同源的基因组。
②真核细胞基因转录产物为单顺反子(monocistron),即一个结构基因转录、翻译成一个mRNA分子,一条多肽链。
③存在大量重复序列,即在整个DNA中有许多重复出现的核苷酸顺序,重复序列长度可长可短,短的仅含两个核苷酸,长的多达数百、乃至上千。重复频率也不尽相同;高度重复序列重复频率可达106次,包括卫星DNA、反向重复序列和较复杂的重复单位组成的重复序列;中度重复序列可达103~104次,如为数众多的Alu家族序列,KpnI家族,Hinf家族序列,以及一些编码区序列如rRNA基因、tRNA基因、组蛋白基因等;单拷贝或低度重复序列,指在整个基因组中只出现一次或很少几次的核苷酸序列,主要是编码蛋白质的结构基因,在人基因组中占约60~65%,因此所含信息量最大。
④基因组中不编码的区域多于编码区域。
⑤基因是不连续的,在真核生物结构基因的内部存在许多不编码蛋白质的间隔序列(interveningsequences),称为内含子(intron),编码区则称为外显子(exon)。内含子与外显子相间排列,转录时一起被转录下来,然后RNA中的内含子被切掉,外显子连接在一起成为成熟的mRNA,作为指导蛋白质合成的模板。
⑥基因组远大于原核生物的基因组,具有许多复制起点,而每个复制子的长度较小。
2.原核生物基因组结构特点
①基因组较小,没有核膜包裹,且形式多样,如病毒基因组可能是DNA,也可能是RNA,可能是单链的,也可能是双链的,可能是闭环分子,也可能是线性分子;细菌染色体基因组则常为环状双链DNA分子,并与其中央的RNA和支架蛋白构成一致密的区域,称为类核(nucleoid)。
②功能相关的结构基因常常串连在一起,并转录在同一个mRNA分子中,称为多顺反子mRNA(polycistronic mRNA),然后再加工成各种蛋白质的模板mRNA。
③DNA分子绝大部分用于编码蛋白质,不编码部分(又称间隔区)通常包含控制基因表达的顺序。例如,噬菌体ψx 174中只有5%是非编码区。
④基因重叠是病毒基因组的结构特点,即同一段DNA片段能够编码两种甚至三种蛋白质分子。
⑤除真核细胞病毒外,基因是连续的,即不含内含子序列。
(三)限制性片段长度多态性
随着对基因认识的不断深入,发现在同种生物的不同个体之间,尽管其蛋白质产物的结构和功能完全相同或仅存在着细微的差异,但在DNA水平却存在着差异,尤其在不编码蛋白质的区域以及没有重要调节功能的区域表现更为突出。这种不影响生物体表型的DNA突变被称为中性突变。
分子生物学技术的不断发展已使得从DNA水平直接分析这类突变成为可能。
目前应用较多且成熟的方法是限制性片段长度多态性(Restriction fragment length polymorphism,RFLP)。即当DNA序列中某一个碱基发生突变,使突变所在部位的DNA序列获得或丢失某种限制性核酸内切酶位点;或当DNA分子内部发生较大的顺序突变如缺失、重复、插入,或DNA高变区内某串联重复顺序的拷贝数不同致使其两侧限制性核酸内切酶位点发生相对位移时,利用相应的限制性核酸内切酶消化此DNA,便会产生与正常不同的限制性片段。这样,在同种生物的不同个体中就会出现不同长度的限制性片段类型。
因为DNA的中性突变常以孟德尔显性遗传方式遗传给下一代,所以对这类突变检测已广泛用于遗传病的诊断、产前诊断、亲子鉴定以及法医学上对罪犯的确认等。
(四)DNA序列分析(DNa sequencing)
DNA的一级结构决定了基因的功能,欲想解释基因的生物学含义,首先必须知道其DNA顺序。因此DNA序列分析是分子遗传学中一项既重要又基本的课题。
1986年由美国学者提出的,目前正在实施的人类基因组计划(human genome project),则是要通过对人类基因组3×109bp全序列的序列分析和人类基因的染色体图谱制定达到了解其结构,认识其功能,即从分子遗传学水平来认识人类自身的结构和功能特征的目的。
核酸的核苷酸序列测定方法已经过近20年的发展,因而测序的具体方法五花八门、种类繁多。但是究其所依据的基本原理,不外乎Sanger的核酸链合成终止法及Maxam和Gilbert的化学降解法两大类。虽然原理不同,但这两种方法都同样生成互相独立的若干组带放射性标记的寡核苷酸,每组寡核苷酸都有固定的起点,但却随机终止于特定的一种或多种残基上。由于DNA链上每一个碱基出现在可变终止端的机会均等,因而上述每一组产物都是一些寡核苷酸的混合物,这些寡核苷酸的长度由某一种特定碱基在原DNA片段上的位置所决定。然后在可以区分长度仅相差一个核苷酸的不同DNA分子的条件下,对各组寡核苷酸进行电泳分析,只要把几组寡核苷酸加样于测序凝胶中若干个相邻的泳道之上,即可从凝胶的放射自显影片上直接读出DNA上的核苷酸顺序。以下分别介绍。
1.Sanger双脱氧链终止法
DNA的合成总是从5′端向3′端进行的。DNA的合成需要模板以及相应的引导核酸链。DNA的合成过程中,在合成的DNA链的3′末端,依据碱基配对的原则,通过生成新的3′,5′-磷酸二酯键,使DNA链合成终止,产生短的DNA链。具体测序工作中,平行进行四组反应,每组反应均使用相同的模板,相同的引物以及四种脱氧核苷酸;并在四组反应中各加入适量的四种之一的双脱氧核苷酸,使其随机地接入DNA链中,使链合成终止,产生相应的四组具有特定长度的、不同长短的DNA链。这四组DNA链再经过聚丙烯酸胺凝胶电泳按链的长短分离开,经过放射自显影显示区带,就可以直接读出被测DNA的核苷酸序列(图15-3)。
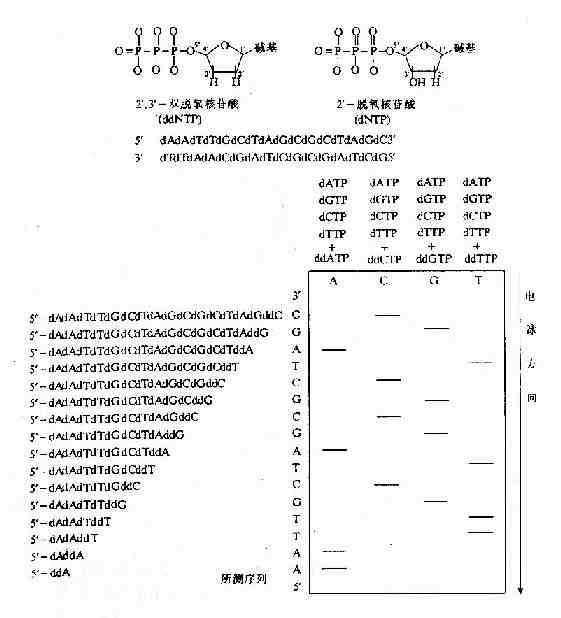
图15-3 双脱氧链终止法测定DNA序列原理示意
2.Maxam?Gilbert DNA化学降解法
这一方法的基本步骤为(1)先将DNA的末端之一进行标记(通常为放射性同位素32P;(2)在多组互相独立的化学反应中分别进行特定碱基的化学修饰;(3)在修饰碱基位置化学法断开DNA链;(4)聚丙烯酰胺凝胶电泳将DNA链按长短分开;(5)根据放射自显影显示区带,直接读出DNA的核苷酸序列(图15-4)。
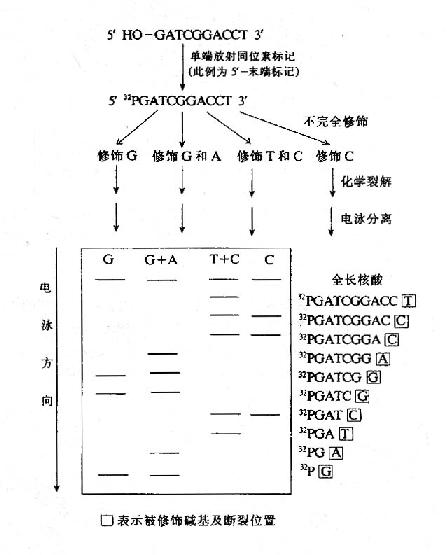
图15-4 化学裂解法测定DNA的核苷酸序列
第三节 DNA的二级结构与功能
(一)DNA的二级结构?双螺旋结构模型(double helixmodel)
1953年,Watson和Crick提出了著名的DNA分子的双螺旋结构模型,揭示了遗传信息是如何储存在DNA分子中,以及遗传性状何以在世代间得以保持。这是生物学发展的重大里程碑。
在DNA双螺旋结构模型建立之前,早在1868年,Miescher已经从脓细胞提取到核酸与蛋白质的复合物,当时称为核素(nuclein)。但核酸在生命活动中的重要地位,却迟至本世纪50年代才被认识。
本世纪20年代,Levene研究了核酸的化学结构并提出四核苷酸假说;40年代末,Avery,Hershey和Chase的实验严密地证实了DNA就是遗传物质;50年代初,Chargaff应用紫外分光光度法结合纸层析等简单技术,对多种生物DNA作碱基定量分析,发现DNA碱基组成有如下规律(表15-3)。
表15-3 不同生物来源的DNA四种碱基比例关系
| DNA来源 |
腺嘌呤(A) |
胸腺嘧啶(T) |
鸟嘌呤(G) |
胞嘧啶(C) |
(A+T)/(G+C) |
| 大肠杆菌 |
25.4 |
24.8 |
24.1 |
25.7 |
1.01 |
| 小麦 |
26.8 |
28.0 |
23.2 |
22.7 |
1.21 |
| 鼠 |
29.7 |
25.6 |
21.9 |
22.8 |
1.21 |
| 猪:肝 |
29.4 |
29.7 |
20.5 |
20.5 |
1.43 |
| 胸腺 |
30.0 |
28.9 |
20.4 |
20.7 |
| 脾 |
29.6 |
29.2 |
20.4 |
20.8 |
| 酵母 |
31.3 |
32.9 |
18.7 |
17.5 |
1.079 |
(1)同一生物的不同组织的DNA碱基组成相同;
(2)一种生物DNA碱基组成不随生物体的年龄、营养状态或者环境变化而改变;
(3)几乎所有的DNA,无论种属来源如何,其腺嘌呤摩尔含量与胸腺嘧啶摩尔含量相同(A]=[T),鸟嘌呤摩尔含量与胞嘧啶摩尔含量相同(G]=[C),总的嘌呤摩尔含量与总的嘧啶摩尔含量相同([A+G]=[C]+[T)。
(4)不同生物来源的DNA碱基组成不同,表现在A+T/G+C比值的不同;
这些结果后来为DNA的双螺旋结构模型提供了一个有力的佐证。
Watson和Crick以立体化学原理为准则,对Wilkins和Franklin的DNa X?射线衍射分析结果加以研究,提出了DNA结构的双螺旋模式,其主要内容如下:
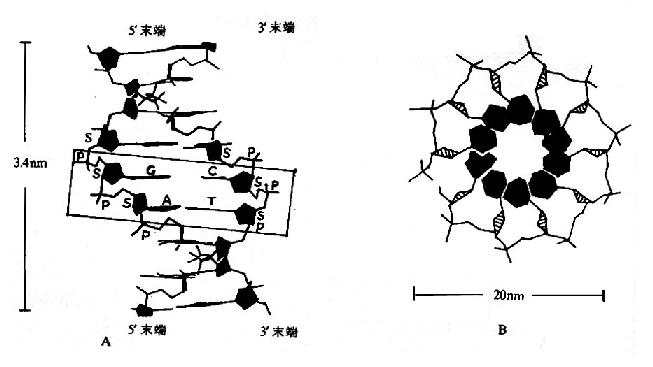
图15-5 DNA的双螺旋结构模式
A.正面观:长方框内有详细说明,S代表脱氧核糖。
B.俯视:涂黑的是碱基,此处全部碱基都是嘧啶,只看到糖的侧面略呈三角形,最外围是磷酸及其酯键。
(1)在DNA分子中,两股DNA链围绕一假想的共同轴心形成一右手螺旋结构,双螺旋的螺距为3.4nm,直径为2.0nm。(图15-5,?A,B)。
(2)链的骨架(backbone)由交替出现的、亲水的脱氧核糖基和磷酸基构成,位于双螺旋的外侧。
(3)碱基位于双螺旋的内侧,两股链中的嘌呤和嘧啶碱基以其疏水的、近于平面的环形结构彼此密切相近,平面与双螺旋的长轴相垂直。一股链中的嘌呤碱基与另一股链中位于同一平面的嘧啶碱基之间以氢链相连,称为碱基互补配对或碱基配对(base pairing),碱基对层间的距离为0.34nm。碱基互补配对总是出现于腺嘌呤与胸腺嘧啶之间(A=T),形成两个氢键;或者出现于鸟嘌呤与胞嘧啶之间(G=C),形成三个氢键。(图15-6)。
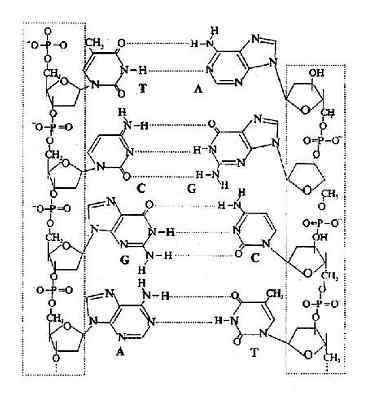
图15-6 A-T,G-C间的氢键形成
(4)DNA双螺旋中的两股链走向是反平行的,一股链是5′→3′走向,另一股链是3′→5′走向。两股链之间在空间上形成一条大沟(major groove)和一条小沟(minor groove),这是蛋白质识别DNA的碱基序列,与其发生相互作用的基础。
DNA双螺旋的稳定由互补碱基对之间的氢键和碱基对层间的堆积力(base?stacking force)维系。DNA双螺旋中两股链中碱基互补的特点,逻辑地预示了DNA复制过程是先将DNA分子中的两股链分离开,然后以每一股链为模板(亲本),通过碱基互补原则合成相应的互补链(复本),形成两个完全相同的DNA分子。因为复制得到的每对链中只有一条是亲链,即保留了一半亲链,将这种复制方式称为DNA的半保留复制(semi?conservativereplication)。后来证明,半保留复制是生物体遗传信息传递的最基本方式。
DNA双螺旋是核酸二级结构的重要形式。双螺旋结构理论支配了近代核酸结构功能的研究和发展,是生命科学发展史上的杰出贡献。
(二)DNA结构的多态性
Watson和Crick提出的DNA双螺旋结构属于B型双螺旋,它是以在生理盐溶液中抽出的DNA纤维在92%相对湿度下进行X-射线衍射图谱为依据进行推测的,这是DNA分子在水性环境和生理条件下最稳定的结构。然而以后的研究表明DNA的结构是动态的。在以钾或绝作反离子,相对湿度为75%时,DNA分子的X-射线衍射图给出的是A构象,A-DNA每螺旋含11个碱基对,而且变成A-DNA后,大沟变窄、变深,小沟变宽、变浅。由于大沟、小沟是DNA行使功能时蛋白质的识别位点,所以由B-DNA变为A-DNA后,蛋白质对DNA分子的识别也发生了相应变化。
一般说来,A-T丰富的DNA片段常呈B-DNA。采用乙醇沉淀法纯化DNA时,整个过程中,大部分DNA由B-DNA经过C-DNA,最终变构为A-DNA。若DNA双链中一条链被相应的RNA链所替换,会变构成A-DNA。当DNA处于转录状态时,DNA模板链与由它转录所得的RNA链间形成的双链就是A-DNA。由此可见A-DNA构象对基因表达有重要意义。此外,B-DNA双链都被RNA链所取代而得到由两条RNA链组成的双螺旋结构也是A-DNA。除A-DNA、B-DNA螺旋外,还存在B′-DNA、C-DNA、D-DNA等,其结构参数见表15-4。
表15-4 不同右手双螺旋DNA的结构参数
| 双螺旋 |
碱基倾 |
碱基夹 |
碱基间距 |
螺距 |
每轮碱 |
小沟宽/nm× |
大沟宽nm× |
|
角/(°) |
角(°) |
/nm |
/nm |
基数 |
小沟宽nm |
大沟宽nm |
| B-DNA |
0 |
36.0 |
0.337 |
3.4 |
10 |
0.57×0.75 |
1.17×0.85 |
| C-DNA |
6 |
38.0 |
0.331 |
3.1 |
9.3 |
0.48×0.79 |
1.05×0.75 |
| D-DNA |
|
45.0 |
0.303 |
|
|
0.13×0.67 |
0.89×0.58 |
| A-DAN |
20 |
32.7 |
0.256 |
2.8 |
11 |
1.10×0.28 |
0.27×1.35 |
总之,DNA的双螺旋结构永远处于动态平衡中,DNA分子构象的变化与糖基和碱基之间空间相对位置有关。
1979年,Wang和Rich等人在研究人工合成的CGCGCG单晶的X-射线衍射图谱时出人意料地发现这种六聚体的构象与上面讲到的完全不同。它是左手双螺旋,与右手螺旋的不同是螺距延长(4.5nm左右),直径变窄(1.8nm),每个螺旋含12个碱基对,分子长链中磷原子不是平滑延伸而是锯齿形排列,有如“之”字形一样,因此叫它Z构象(英文字Zigzag的第一个字母)。还有,这一构象中的重复单位是二核苷酸而不是单核苷酸;而且Z?DNA只有一个螺旋沟,它相当于B构象中的小沟,它狭而深,大沟则不复存在(图15-7)。进一步的分析还证明,Z-DNA的形成是DNA单链上出现嘌呤与嘧啶交替排列所成的。比如CGCGCGCG或者CACACACA。
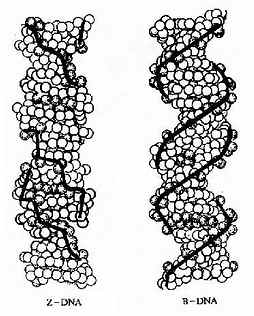
图15-7 Z-DNA和B-DNA
Z-DNA有什么生物学意义呢?应当指出Z-DNA的形成通常在热力学上是不利的。因为Z-DNA中带负电荷的磷酸根距离太近了,这会产生静电排斥。但是,DNA链的局部不稳定区的存在就成为潜在的解链位点。DNA解螺旋却是DNA复制和转录等过程中必要的环节,因此认为这一结构与基因调节有关。比如SV40增强子区中就有此结构,又如鼠类微小病毒DNS复制区起始点附近有GC交替排列序列。此外,DNA螺旋上沟的特征在其信息表达过程中起关键作用。调控蛋白都是通过其分子上特定的氨基酸侧链与DNA双螺旋沟中的碱基对一侧的氢原子供体或受体相互作用,形成氢键从而识别DNA上的遗传信息的。大沟所带的遗传信息比小沟多。沟的宽窄和深浅也直接影响到调控蛋白质对DNA信息的识别。Z?DNA中大沟消失,小沟狭而深,使调控蛋白识别方式也发生变化。这些都暗示Z?DNA的存在不仅仅是由于DNA中出现嘌呤一啶嘧交替排列之结果,也一定是在漫漫的进化长河中对DNA序列与结构不断调整与筛选的结果,有其内在而深刻的含意,只是人们还未充分认识而已。
DNA构象的可变性,或者说DNA二级结构的多态性的发现拓宽了人们的视野。原来,生物体中最为稳定的遗传物质也可以采用不同的姿态来实现其丰富多采的生物学功能。
多年来,DNA结构的研究手段主要是X射线衍射技术,其结果是通过间接观测多个DNA分子有关结构参数的平均值而获得的。同时,这项技术的样品分析条件使被测DNA分子与天然状态相差甚远。因此,在反映DNA结构真实性方面这种方法存在着缺陷。1989年,应用扫描隧道显微镜(scanning tummelingmicroscopy,STM)研究DNA结构克服了上述技术的缺陷。这种先进的显微技术,不仅可将被测物放大500万倍,且能直接观测接近天然条件下单个DNA分子的结构细节。STM技术的应用是DNA结构研究中的重要进展,可望在探索DNA结构的某些未知点上展示巨大潜力。
(三)DNA结构的不均一性(heterogeneity)
在DNA的一级结构中,四种碱基A,T,C,G远非均匀分布,尽管双螺旋的构型大体相同,但沿着DNA链各处的物理结构不完全相同,各处双螺旋的稳定性也就显示出差别,充分体现了DNA一级结构决定高级结构的原理。其不均一性主要有:
1.反向重复序列(inverted repeats)
又称回文序列(palindrome),它能在DNA或RNA中形成发夹结构。这种回文结构通常是作为一种特别信号,如限制性核酸内切酸(restriction encl闩迥onuclease)及调节蛋白的识别位点,转录终止信号等。
2.富含A/T的序列
在高等生物中,A+T与G+C的含量差不多相等,然而在它们的染色体某一区域,A·T含量可能相当高。如在很多有重要调节功能的DNA区段都富含A·T,特别是在复制起点和启动子的Pribnow框(真核生物为TATA框)的序列中,其对于复制和起始十分重要。因为A-T对只有二条氢键,此处的双链较G-C对处易于解开,有利于起始复合物的形成。
3.嘌呤和嘧啶的排列顺序对双螺旋结构稳定性的影响。
人们考察了十种相邻的二核苷酸对(nearest?neighbor doublets),发现一个非常有趣的现象,那就是碱基组成相同,但嘌呤和嘧啶的排列顺序不同,双螺旋的稳定性具有显著的差异。例如5′Gc3′ 3′G 5′和5′GC 3′ 3′GC 5′的稳定性相差很大,前者的稳定性远大于后。它们的氢键数目是相同的,它们的差别在于相邻碱基之间的堆集力不同。即从嘌呤到嘧啶的方向的碱基堆集作用显著地大于同样组成的嘧啶到嘌呤方向的碱基堆集作用。(这里的方向就是常规的从5′端到3′端的方向)。这是因为前者的嘌呤环和嘧啶环重迭面积大于后者的嘧啶环和嘌呤环的重迭面积,这在B型DNA中确是如此。
根据Gotoh 1981年的研究,十种相邻二核苷酸对的Tm值如表15?所示,单位为℃,所用离子强度为19.5mmol/l Na+。
表15-5 相邻二核苷酸对Tm值
|
3′ |
| A |
T |
G |
C |
| 5′ |
A |
54.50 |
57.02 |
58.42 |
97.73 |
| T |
36.73 |
54.50 |
54.71 |
86.44 |
| G |
86.44 |
97.73 |
85.97 |
136.12 |
| C |
54.71 |
58.42 |
72.55 |
85.97 |
由表15-5可以看到,5′TA 3′ 3′AT5′的Tm值最低。在真核生物中,常可以在?19到?27的位置上看到一个叫做TATA框的结构(又称Hogness框),这是RNA聚合酶的结合位点。在这里RNA聚合酶和有关蛋白质因子形成转录起始复合物。
又如,生命有机体选择UAA作为最有效的终止密码子绝不是偶然的,因为64个三联体密码子中,它与反密码子(假定有的话)形成的互补产物5′UAA3′3′AUU5′的Tm值是最低的一个,即使在生理温度下也是不稳定的。当初有人花了很多工夫去寻找一个不携带氨基酸的专供肽链终止用的tRNA,其实并不存在这种tRNA。肽链的释放是由释放因子RF在起作用。在三种终止密码子中,UAG和UGA常会为突变型的tRNA无义抑制,而UAA则很少发生无义抑制也可能就是这个道理。这也就说明了为什么在肽链终止处常常会出现双重终止密码子。
(四)DNA的变性、复性与分子杂交
DNA双螺旋结构模型,不仅与其生物功能有密切关系,还能解释DNA的重要特性枣变性与复性,这对于深入了解DNA分子结构与功能的关系又有重要意义。
1.DNA变性(denaturation)
指DNA分子由稳定的双螺旋结构松解为无规则线性结构的现象。变性时维持双螺旋稳定性的氢键断裂,碱基间的堆积力遭到破坏,但不涉及到其一级结构的改变。凡能破坏双螺旋稳定性的因素,如加热、极端的pH、有机试剂甲醇、乙醇、尿素及甲酰胺等,均可引起核酸分子变性。变性DNA常发生一些理化及生物学性质的改变:
溶液粘度降低。DNA双螺旋是紧密的刚性结构,变性后代之以柔软而松散的无规则单股线性结构,DNA粘度因此而明显下降。
溶液旋光性发生改变。变性后整个DNA分子的对称性及分子局部的构性改变,使DNA溶液的旋光性发生变化。
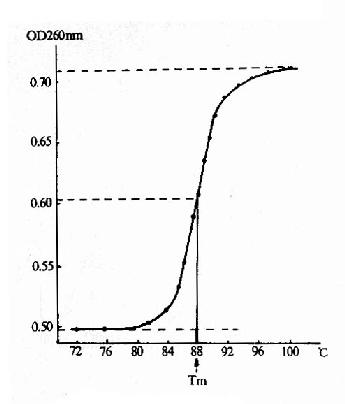
15-8 核酸的解链曲线
增色效应(hyperchromiceffect)。指变性后DNA溶液的紫外吸收作用增强的效应。DNA分子中碱基间电子的相互作用使DNA分子具有吸收260nm波长紫外光的特性。在DNA双螺旋结构中碱基藏入内侧,变性时DNA双螺旋解开,于是碱基外露,碱基中电子的相互作用更有利于紫外吸收,故而产生增色效应。
对双链DNA进行加热变性,当温度升高到一定高度时,DNA溶液在260nm处的吸光度突然明显上升至最高值,随后即使温度继续升高,吸光度也不再明显变化。若以温度对DNA溶液的紫外吸光率作图,得到的典型DNA变性曲线呈S型(图15?8)。可见DNA变性是在一个很窄的温度范围内发生的。通常将核酸加热变性过程中,紫外光吸收值达到最大值的50%时的温度称为核酸的解链温度,由于这一现象和结晶的融解相类似,又称融解温度(Tm,meltingtemperature)。在Tm时,核酸分子内50%的双螺旋结构被破坏。特定核酸分子的Tm值与其G+C所占总碱基数的百分比成正相关,两者的关系可表示为:
Tm=69.3+0.41(%G+C)
一定条件下(相对较短的核酸分子),Tm值大小还与核酸分子的长度有关,核酸分子越长,Tm值越大;另外,溶液的离子强度较低时,Tm值较低,融点范围也较宽,反之亦然,因此DNA制剂不应保存在离子强度过低的溶液中。
2.DNA复性(renaturation)
指变性DNA在适当条件下,二条互补链全部或部分恢复到天然双螺旋结构的现象,它是变性的一种逆转过程。热变性DNA一般经缓慢冷却后即可复性,此过程称之为退火(annealing)。这一术语也用以描述杂交核酸分子的形成(见后)。DNA的复性不仅受温度影响,还受DNA自身特性等其它因素的影响:
温度和时间。一般认为比Tm低25℃左右的温度是复性的最佳条件,越远离此温度,复性速度就越慢。复性时温度下降必须是一缓慢过程,若在超过Tm的温度下迅速冷却至低温(如4℃以下),复性几乎是不可能的,核酸实验中经常以此方式保持DNA的变性(单链)状态。这说明降温时间太短以及温差大均不利于复性。
DNA浓度。溶液中DNA分子越多,相互碰撞结合的机会越大。
DNA顺序的复杂性。简单顺序的DNA分子,如多聚(A)和多聚(U)这二种单链序列复性时,互补碱基的配对较易实现。而顺序复杂的序列要实现互补,则困难得多。在核酸复性研究中,定义了一个Cot的术语,(Co为单链DNA的起始浓度,t是以秒为单位的时间),用以表示复性速度与DNA顺序复杂性的关系。在探讨DNA顺序对复性速度的影响时,将温度、溶剂离子强度、核酸片段大小等其它影响因素均予以固定,以不同程度的核酸分子重缔合部分(在时间t时的复性率)对Cot作图,可以得到如图15-9所示的曲线。曲线上方为示复杂性的核酸分子的非重复碱基对数。如多聚(A)的复杂性为1,重复的(ATGC)n组成的多聚体的复杂性为4,分子长度是105核苷酸对的非重复DNA的复杂性为105。原核生物基因组均为非重复顺序,故以非重复核苷酸对表示的复杂性直接体现基因组大小(图上方的箭头所指为基因大小),对于真核生物基因组中的非重复片段也是如此。在标准条件下(一般为0.18ml/L阳离子浓度,400核苷酸长的片段)测得的复性率达0.5时的Cot值(称Cot1/2),与核苷酸对的复杂性成正比。对于原核生物核酸分子,此值可代表基因组的大小及基因组中核苷酸对的复杂程度。真核基因组中因含有许多不同程度的重复序列(repetitive sequence),所得到的Cot曲线更为复杂。
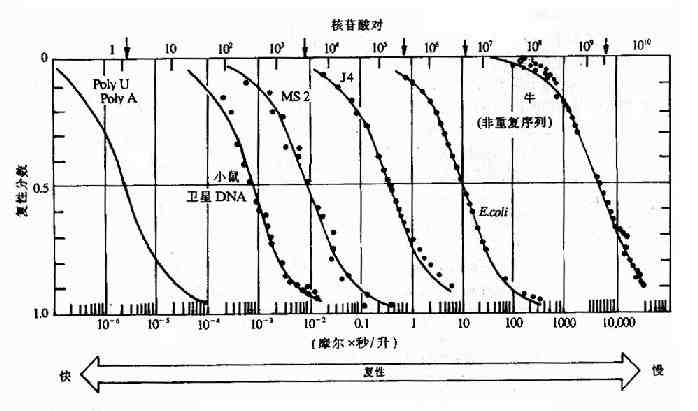
图15-9 不同物种核酸的Cot曲线
DNA的变性和复性原理,现已在医学和生命科学上得到广泛的应用。如核酸杂交与探针技术,聚合酶链反应(polymerasechain reaction,PCR)技术等。
3.分子杂交:(hybridization)
不同来源的核酸变性后,合并在一处进行复性,这时,只要这些核酸分子的核苷酸序列含有可以形成碱基互补配对的片段,复性也会发生于不同来源的核酸链之间,形成所谓的杂化双链(heterodup lex),这个过程称为杂交(hybridization)图15-10,I)。杂交可以发生于DNA与DNA之间,也可以发生于RNA与RNA之间和DNA与RNA之间。例如,一段天然的DNA和这段DNA的缺失突变体(假定这种突变是DNA分子中部丢失了若干碱基对)一起杂交,电子显微镜下可以看到杂化双链中部鼓起小泡。测量小泡位置和长度,可确定缺失突变发生的部位和缺失的多少。核酸杂交技术是目前研究核酸结构、功能常用手段之一,不仅可用来检验核酸的缺失、插入,还可用来考察不同生物种类在核酸分子中的共同序列和不同序列以确定它们在进化中的关系。其应用当然远不止于确定突变位置这一例(图15-10Ⅱ)。
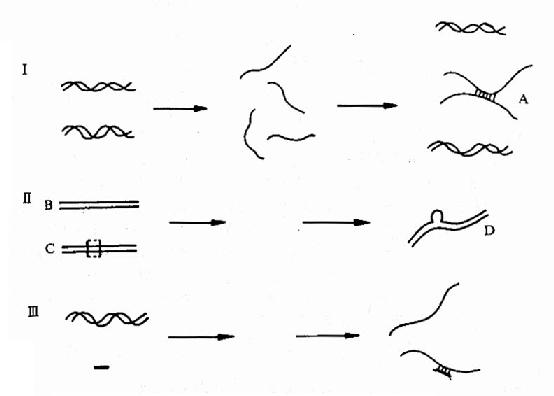
图15-10 核酸杂交及其应用示意图
Ⅰ.变性、复性和杂交。粗细线分别代表不同DNA。A是杂化双链
Ⅱ.突变体的鉴别。B代表天然DNA;C是B的缺失突变体;虚线框内是已缺失的部分;
D是显示从天然DNA链鼓出小泡 Ⅲ.粗线代表探针,粗线上的X表示放射性标记
在核酸杂交的基础上发展起来的一种用于研究和诊断的非常有用的技术称探针技术(Probe)。一小段(例如十数个至数百个)核苷酸聚合体的单链,有放射性同位素如32P、35S或生物素标记其末端或全链,就可作为探针。把待测DNA变性并吸附在一种特殊的滤膜,例如硝酸纤维素膜上。然后把滤膜与探针共同培育一段时间,使发生杂交。用缓冲液冲洗膜。由于这种滤膜能较牢固地吸附双链的核酸,单链的在冲洗时洗脱了。带有放射性的探针若能与待测DNA结合成杂化双链,则保留在滤膜上。通过同位素的放射自显影或生物素的化学显色,就可判断探针是否与被测的DNA发生杂交。有杂交现象则说明被测DNA与探针有同源性(homogeneity),即二者的碱基序列是可以互补的。例如:想知道某种病毒是否和某种肿瘤有关,可把病毒的DNA制成探针。从肿瘤组织提取DNA,与探针杂交处理后,有杂化双链的出现,就说明两种DNA之间有同源性。这不等于可以说这种病毒引起肿瘤,但至少这是可以继续深入研究下去的一条重要线索。
探针技术(图15-10Ⅲ)在遗传性疾病诊断上已开始应用。例如诊断地中海贫血或血红蛋白病,可以由已确诊的病人白细胞中提取DNA,这就是诊断探针。用诊断探针检查,不但可以对有症状患者进行确诊,还可以发现一些没有症状的隐性遗传性疾病。从胎儿的羊水也可以提取到少量DNA。由于探针技术比较灵敏,就使遗传性疾病的产前诊断较为容易办得到了。杂交和探针技术是许多分子生物学技术的基础,在生物学和医学的研究中,以及临床诊断中得到了日益广泛的应用。
第四节 DNA的三级结构与功能
(一)DNA超螺旋
双螺旋DNA进一步扭曲盘绕则形成其三级结构,超螺旋是DNA三级结构的主要形式。自从1965年Vinograd等人发现多瘤病毒的环形DNA的超螺旋以来,现已知道绝大多数原核生物都是共价封闭环(covalentlyclosed circle,CCC)分子,这种双螺旋环状分子再度螺旋化成为超螺旋结构(superhelix或supercoil),如图15-11所示。有些单链环形染色体(如φ×174)或双链线形染色体(如噬菌体入),在其生活周期的某一阶段,也必将其染色体变为超螺旋形式。对于真核生物来说,虽然其染色体多为线形分子但其DNA均与蛋白质相结合,两个结合点之间的DNA形成一个突环(loop)结构,类似于CCC分子,同样具有超螺旋形式。超螺旋按其方向分为正超螺旋和负超螺旋两种。真核生物中,DNA与组蛋白八聚体形成核小体结构时,存在着负超螺旋。研究发现,所有的DNA超螺旋都是由DNA拓扑异构酶产生的。
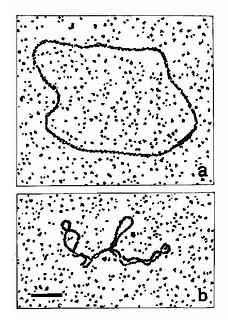
图15-11 Open?circular(a) andsupercoiled (b) forms of PM2 virus DNA,Bar
represents 0.2μm.(By courtesy ofDr Lesley Coggins)
(二)染色质和核小体
1.染色质
真核生物的染色体(chromasome)在细胞生活周期的大部分时间里都是以染色质(chromatin)的形式存在的。染色质是一种纤维状结构,叫做染色质丝,它是由最基本的单位枣核小体(nucleosome)成串排列而成的。DNA是染色体的主要化学成分,也是遗传信息的载体,约占染色体全部成分的27%,另外组蛋白和非组蛋白占66%,RNA占6%。
组蛋白(histones)是一种碱性蛋白质,等电点一般在PH10.0以上,其特点是富含二种碱性氨基酸(赖氨酸和精氨酸),根据这两种氨基酸在蛋白质分子中的相对比例,将组蛋白分为五种类型(表15-6)。
表15-6 五种组蛋白分子的基本参数
| 种类 |
类型 |
碱性氨基酸 |
酸性 氨基酸 |
碱性氨基酸/酸性氨基酸 |
氨基酸 残基数 |
分子量 |
核小体 上位置 |
| Lys |
Arg |
Lys/Arg |
| H1 |
极度富含Lys |
29% |
1% |
29 |
5% |
5.4 |
215 |
23 000 |
连接* |
| H2A |
|
11% |
9% |
1.2 |
15% |
1.4 |
129 |
14 500 |
核心 |
| H2B |
″ |
16% |
6% |
2.7 |
13% |
1.7 |
125 |
13 774 |
″ |
| H3 |
极度富含Lys+富含Arg |
10% |
13% |
0.78 |
13% |
1.8 |
135 |
15 324 |
″ |
| H4 |
″ |
11% |
14% |
0.79 |
10% |
2.5 |
102 |
11 282 |
″ |
*现已证明:H1是与核小体的核心颗粒相当靠近的,认为它位于连接DNA上,只是一种习惯说法。
五种组蛋白在同一生物的不同组织中完全一样,在不同的真核生物中也很相似。组蛋白对染色体中DNA的包装有十分重要的作用。
2.核小体
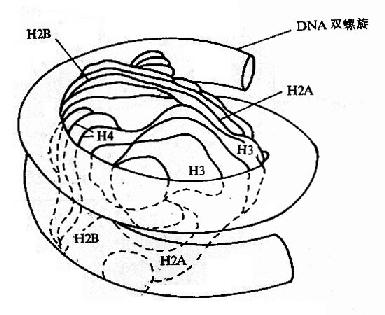
图15-12A DNA的高级结构
核小体是构成染色质的基本结构单位,使得染色质中DNA、RNA和蛋白质组织成为一种致密的结构形式。核小体由核心颗粒(core particle)和连接区DNA(linker DNA)二部分组成,在电镜下可见其成捻珠状,前者包括组蛋白H2A,H2B,H3和H4各两分子构成的致密八聚体(又称核心组蛋白),以及缠绕其上一又四分之三圈长度为146bp的DNA链;后者包括两相邻核心颗粒间约60bp的连接DNA和位于连接区DNA上的组蛋白H1(图15-12),连接区使染色质纤维获得弹性。核小体是DNA紧缩的第一阶段,在此基础上,DNA链进一步折叠成每圈六个核小体,直径30nm的纤维状结构,这种30nm纤维再扭曲成襻,许多襻环绕染色体骨架(Scaffold)形成棒状的染色体,最终压缩将近一万倍。这样,才使每个染色体中几厘米长(如人染色体的DNA分子平均长度为4cm)的DNA分子容纳在直径数微米(如人细胞核的直径为6-7μm)的细胞核中。
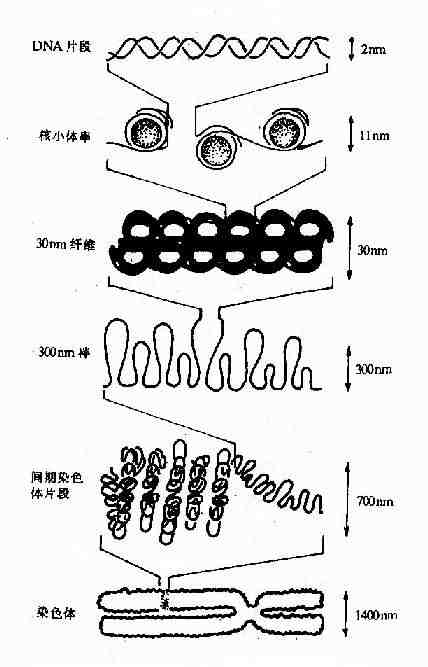
图15-12B DNA的高级结构-从核小体至染色体
核小体的形成以及DNA超螺旋结构与功能的关系还不十分清楚,可能与基因的转录调节控制有关。
第五节 RNA的结构与功能
DNA是遗传信息的载体,遗传信息的作用通常由蛋白质的功能来实现,但DNA并非蛋白质合成的直接模板,合成蛋白质的模板是RNA。正常细胞遗传信息的流向是:
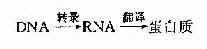
与DNA相比,RNA种类繁多,分子量相对较小,一般以单股链存在,但可以有局部二级结构,其碱基组成特点是含有尿嘧啶(uridin,U)而不含胸腺嘧啶,碱基配对发生于C和G与U和A之间,RNA碱基组成之间无一定的比例关系,且稀有碱基较多。此外,tRNA还具有明确的三级结构。
表15-7 RNA的分类
|
细胞核和胞液 |
线粒体 |
功能 |
| 核蛋白体RNA |
rRNA |
mt tRNA |
核蛋白体组成成分 |
| 信使RNA |
mRNA |
mt mRNA |
蛋白质合成模板 |
| 转运RNA |
tRNA |
mt tRNA |
转运氨基酸 |
| 不均一核RNA |
hnRNA |
|
成熟mRNA的前体 |
| 小核RNA |
snRNA |
|
参与hnRNA的剪接、转运 |
| 小胞浆RNA |
scRNA/7SL-RNA |
|
蛋白质内质网定位合成的信号识别体的组成成分 |
注:原核细胞不含后3种RNA
(一)信使RNA(mRNA)与不均一核RNA(hnRNA)
遗传信息从DNA分子抄录到RNA分子中的过程称为转录(transcription)。在真核生物中,最初转录生成的RNA称为不均一核RNA(heterogeneous nuclearRNA,hnRNA),然而在细胞浆中起作用,作为蛋白质的氨基酸序列合成模板的是mRNA(messengerRNA)。hnRNA是mRNA的未成熟前体。两者之间的差别主要有两点:一是hnRNA核苷酸链中的一些片段将不出现于相应的mRNA中,这些片段称为内含子(intron),而那些保留于mRNA中的片段称为外显子(exon)。也就是说,hnRNA在转变为mRNA的过程中经过剪接,被去掉了一些片段,余下的片段被重新连接在一起;二是mRNA的5′末端被加上一个m7pGppp帽子,在mRNA3′末端多了一个多聚腺苷酸(polyA)尾巴。mRNA从5′末端到3′末端的结构依次是5′帽子结构,5′末端非编码区,决定多肽氨基酸序列的编码区,3′末端非编码区,和多聚腺苷酸尾巴。多聚腺苷酸尾一般由数十个至一百几十个腺苷酸连接而成。随着mRNA存在时间的延续,这段聚A尾巴慢慢变短。因此,目前认为这种3′末端结构可能与增加转录活性以及使mRNA趋于相对稳定有关。原核生物的mRNA没有这种首、尾结构。
图15-13 hnRNA与mRNA的结构比较
(涂斜线者为外显子,空白者为内含子)
1961年,Jacob和Monod首先提出了mRNA的概念。在真核细胞中,由于蛋白质是在胞浆中而不是在核内合成,因此显然要求有一个中间物将DNA上的遗传信息传递至胞浆中。后来的研究证实,这种中间物即信使RNA。?mRNA的核苷酸序列与DNA序列相应,决定着合成蛋白质的氨基酸序列。它如何指导氨基酸以正确的顺序连接起来呢?不同的mRNA碱基组成和排列顺序都不同,但都只有A,G,C,U4种碱基。如果一个碱基就可以决定一个氨基酸,则只有四种变化方式,如果两个碱基决定一个氨基酸,则只有16种变化方式,都不能满足20种氨基酸的需要。1961年Crick和Brenner的实验得出了三个核苷酸编码一个氨基酸的结论,并将这种三位一体的核苷酸编码称做遗传密码(genetic code)或三联体密码,这样就可以有64种不同的密码,但此情况下必须假定有一些氨基酸使用两个以上的密码。这一假定很快就被证明是对的。遗传密码具有下列特征:
(1)三个核苷酸组成一个密码子,每个密码子由三个前后相联的核苷酸组成,一个密码子只为一种氨基酸编码。共有64个密码子;
(2)密码子之间不重叠使用核苷酸,也无核苷酸间隔;
(3)一种氨基酸可有多个密码子,这个特点称为密码子的简并性;
(4)密码子的通用性,所有生物从最低等的病毒直至人类,蛋白质合成都使用同一套密码子表(表15-8),仅有极少的例外,如特殊细胞器线粒体,叶绿体所用的密码稍有不同。(表15-9)。
表15-8 通用遗传密码及相应的氨基酸
| 第一个核苷酸5′ |
第二个核苷酸 |
第三个核苷酸3′ |
| U |
C |
A |
G |
| U |
苯丙氨酸 |
丝氨酸 |
酪氨酸 |
半胱氨酸 |
U |
| 苯丙氨酸 |
丝氨酸 |
酪氨酸 |
半胱氨酸 |
C |
| 亮氨酸 |
丝氨酸 |
终止码 |
终止码 |
A |
| 亮氨酸 |
丝氨酸 |
终止码 |
色氨酸 |
G |
| C |
亮氨酸 |
脯氨酸 |
组氨酸 |
精氨酸 |
U |
| 亮氨酸 |
脯氨酸 |
组氨酸 |
精氨酸 |
C |
| 亮氨酸 |
脯氨酸 |
谷氨酰胺 |
精氨酸 |
A |
| 亮氨酸 |
脯氨酸 |
谷氨酰胺 |
精氨酸 |
G |
| A |
异亮氨酸 |
苏氨酸 |
天冬酰胺 |
丝氨酸 |
U |
| 异亮氨酸 |
苏氨酸 |
天冬酰胺 |
丝氨酸 |
C |
| 异亮氨酸 |
苏氨酸 |
赖氨酸 |
精氨酸 |
A |
| 蛋氨酸 |
苏氨酸 |
赖氨酸 |
精氨酸 |
G |
| G |
缬氨酸 |
丙氨酸 |
天冬氨酸 |
甘氨酸 |
U |
| 缬氨酸 |
丙氨酸 |
天冬氨酸 |
甘氨酸 |
C |
| 缬氨酸 |
丙氨酸 |
谷氨酸 |
甘氨酸 |
A |
| 缬氨酸 |
丙氨酸 |
谷氨酸 |
甘氨酸 |
G |
表15-9 通用遗传密码与线粒体遗传密码之间的一些差异
| 密码子 |
通用编码 |
线粒体编码 |
| 哺乳动物 |
果蝇 |
酵母菌 |
植物 |
| UGA |
终止码 |
色氨酸 |
色氨酸 |
色氨酸 |
终止码 |
| AUA |
异亮氨酸 |
蛋氨酸 |
蛋氨酸 |
蛋氨酸 |
异亮氨酸 |
| CUA |
亮氨酸 |
亮氨酸 |
亮氨酸 |
苏氨酸 |
亮氨酸 |
| AGA |
精氨酸 |
终止码 |
丝氨酸 |
精氨酸 |
精氨酸 |
| AGA |
注:下标横线者为与通用编码不同的编码
究竟哪一个密码子为哪一种氨基酸编码,即密码子与氨基酸之间的对应关系已在60年代研究解决了。1964年Nirenberg用一种RNA聚合酶体外合成了多聚尿苷酸、多聚腺苷酸等多聚核苷酸,将这些多聚核苷酸分别用于蛋白质的体外合成。发现,当所用的多聚核苷酸为多聚尿苷酸时,只有多聚苯丙氨酸合成,这意味着UUU为苯丙氨酸编码;用其它多聚核苷酸进行相应的实验后发现,CCC为脯氨酸编码,而AAA为赖氨酸编码;其后,有人又用核苷酸比例为已知,但是核苷酸序列随机的多聚核苷酸,以及用已知序列的含两种或两种以上核苷酸的多聚核苷酸进行相应的实验,将结果加以数理统计处理,又解读了一批密码子,其中包括三个终止码,最后,还有一些密码子是通过合成已知序列的三聚核苷酸与核蛋白体和载有放射性同位素标记的氨基酸的tRNA共沉淀原理予以解读的。在所有密码子中,AUG不仅为蛋氨酸编码,而且又是翻译(translation,以mRNA上的遗传信息指导核蛋白体上多肽链合成的过程)的起始信号,UAA、UAG和UGA不为任何氨基酸编码,而是作为翻译的终止信号,统称为终止码(stop codon),又常被叫作无意义码(nonsense codon)。
大多数氨基酸是由一个以上的密码子所编码。这个事实提出了一个问题:编码同一种氨基酸的一组密码子的使用频率是否都相同?细致的分析表明,无论是原核生物,还是高等真核生物,密码子的使用频率并不是平均的,有些密码子的使用率很高,有些则几乎不使用,其使用频率主要与细胞内tRNA含量呈正相关。
(二)转运RNA(tRNA)
tRNA(transfer RNA)是蛋白质合成中的接合器分子。tRNA分子有100多种,各可携带一种氨基酸,将其转运到核蛋白体上,供蛋白质合成使用。tRNA是细胞内分子量最小的一类核酸,由70~120核苷酸构成,各种tRNA无论在一级结构上,还是在二、三级结构上均有一些共同特点。tRNA中含有10%~20%的稀有碱基(rare bases),如:甲基化的嘌呤mG、mA,双氢尿嘧啶(DHU)、次黄嘌呤等等。此外,tRNA内还含有一些稀有核苷,如:胸腺嘧啶核糖核苷,假尿嘧啶核苷(Ψ,pseudouridine)等。胸腺嘧啶一般存在于DNA中;在假尿嘧啶核苷中,不是通常嘧啶环中1位氮原子,而是嘧啶环中的5位碳原子与戊糖的1′位碳原子之间形成糖苷键。
tRNA分子内的核苷酸通过碱基互补配对形成多处局部双螺旋结构,未成双螺旋的区带构成所谓的环和襻。现发现的所有tRNA均可呈现图15-14所示的这种所谓的三叶草样(clover leafpattern)二级结构。在此结构中,从5′末端起的第一个环是DHU环,以含二氢尿嘧啶为特征;第二个环为反密码子环,其环中部的三个碱基可以与mRNA中的三联体密码子形成碱基互补配对,构成所谓的反密码子(anticodon),在蛋白质合成中起解读密码子,把正确的氨基酸引入合成位点的作用;第三个环为TΨ环,以含胸腺核苷和假尿苷为特征;在反密码子环与TΨ环之间,往往存在一个襻,由数个乃至二十余个核苷酸组成,所有tRNA3′末端均有相同的CCA-OH结构,tRNA所转运的氨基酸就连接在此末端上。(图15-14A)
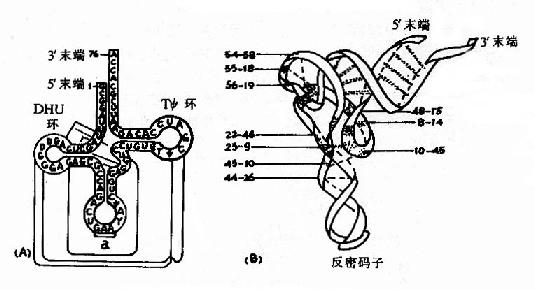
图15-14 tRNA的二级与三级结构
A.二级结构(a示反密码环及反密码)
B.三级结构(数字示可能的非常见核苷酸对相互作用)
通过X-射线衍射等结构分析方法,发现tRNA的共同三级结构均呈倒L形(图15-14B),其中3′末端含CCA?OH的氨基酸臂位于一端,反密码子环位于另一端,DHU环和TΨ环虽在二级结构上各处一方,但在三级结构上却相互邻近。tRNA三级结构的维系主要是依赖核苷酸之间形成的各种氢键。各种tRNA分子的核苷酸序列和长度相差较大,但其三级结构均相似,提示这种空间结构与tRNA的功能有密切关系。
(三)核蛋白体RNA(rRNA)
核蛋白体RNA(ribosomalRNA)是细胞内含量最多的RNA,约占RNA总量的80%以上,是蛋白质合成机器枣核蛋白体(核糖体)(ribosome)的组成成分。核糖体蛋白(ribosmal protein,rp)有数十种,大多是分子量不大的多肽类,分布在核蛋白体大亚基的蛋白称为rpl,在小亚基的称rps。
原核生物和真核生物的核蛋白体均由易于解聚的大、小亚基组成。对大肠杆菌核蛋白体的研究发现其质量中三分之二是rNRA,三分之一是蛋白质。rRNA分为5S、16S、23S三种。S是大分子物质在超速离心沉降中的一个物理学单位,可反映分子量的大小。小亚基由16SrRNA和21种rps构成,大亚基由5S、23s rRNA和31种 rpl构成。真核生物核蛋白体小业基含18S rRNA和30多种rps,大亚基含28S、5.8S、5S三种rRNA,近50种rpl。各种生物核蛋白体小亚基中的rRNA具有相似的二级结构(图15-15)。
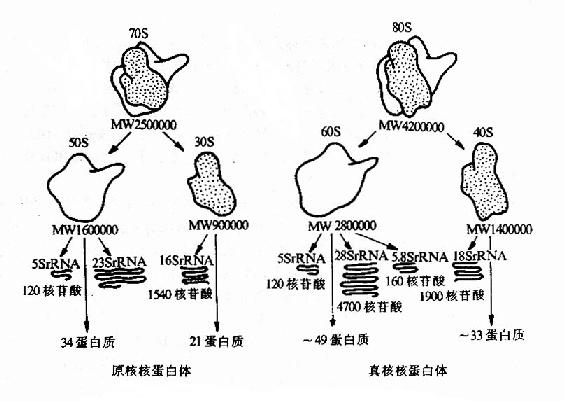
图15-15 原核生物与真核生物核蛋白体的结构比较
(线粒体核蛋白体的结构与原核相似)
无论在试管内或细胞内,大、小亚基都易于组成核蛋白体整体或分离成两部分。几十种多肽是如何互相联结,又怎样与几种rRNA相连的呢?用提纯了的亚基所有的肽和rRNA在试管内混合,发现不需加入酶或ATP就可以自动组装成为有活性的亚基,但rRNA之间却不能互相替代,也即说这种自我组装过程是以rRNA为主导的。虽然所有多肽在组装中也是缺一不可的,但不同的肽可能有酶的作用或起别构效应。现已证明某些核糖体蛋白具有酶的功能,但基中大多数还未弄清其具体作用。
(四)其它RNA分子
小核RNA(snRNA,smallnuclear RNA)存在于真核细胞的细胞核内,是一类称为小核核蛋白体复合体(snRNP)的组成成分,有U1,U2,U4,U5,U6snRNA等,均为小分子核糖核酸,长约106?89个核苷酸,其功能是在hnRNA成熟转变为mRNA的过程中,参与RNA的剪接,并且在将mRNA从细胞核运到细胞浆的过程中起着十分重要的作用(表15-10)。
表15-10 snRNA的种类与功能
| snRNA |
分子大小(核苷酸数) |
功能 |
| U1 |
165 |
结合5′-剪接点 |
| U2 |
185 |
结合于分支点 |
| U5 |
116 |
结合于3′-剪接点 |
| U4 |
145 106 |
装配剪接颗粒 |
| U6 |
小胞浆RNA(scRNA,smallcytosol RNA)又称为7SL?RNA,长约300个核苷酸,主要存在于细胞浆中,是蛋白质定位合成于粗面内质网上所需的信号识别体(signal recognization particle)的组成成分。
小结
核酸是由核苷酸聚合而成的高分子化合物,是所有生物遗传信息的携带者。根据核苷酸分子中戊糖的类型,将核酸分为脱氧核糖核酸(DNA)和核糖核酸(RNA)两大类。
核苷酸由磷酸基、戊糖和含氮碱基组成,碱基包括嘌呤和嘧啶两大类。DNA一般含A、C、G、T四种碱基,RNA含A、C、G、U四种碱基。
四种核苷酸按照一定的排列顺序,通过3′,5′磷酸二酯键相连形成的线形多核苷酸即DNA的一级结构。不同排列顺序的DNA区段构成的特定功能单位即基因,DNA的一级结构决定了基因的功能。
一般将细胞内染色体包含DNA的总体称为基因组。同一物种的基因组DNA含量总是恒定的,不同物种间基因组大小和复杂程度差异极大。真核生物具有复杂的染色体结构,其基因组DNA上存在着单一序列和大量重复序列,大多数真核基因都是不连续的,在成熟RNA中出现的部分称为外显子,在DNA拼接过程中被删除的部分称为内含子。原核生物没有核膜,其DNA与RNA和蛋白质一起形成一个相对集中的区域即类核。原核生物基因组上功能相关的基因常常串连在一起并转录在同一mRNA分子中,形成多顺反子结构。某些病毒中会出现基因重叠。
在进化过程中DNA可能发生突变,不影响生物体表型的DNA突变称为中性突变,中性突变常以孟德称显性遗传方式遗传给下一代,其中的限制性片段长度多态性已被广泛用于遗传病的诊断、产前诊断、亲子鉴定以及法医学上对罪犯的确认等。
双螺旋结构是DNA的二级结构,由戊糖和磷酸基构成的两条主锭以反平行的方式和右手方向相互缠绕,构成双螺旋的骨架。主链由于其亲水性而处于双螺旋的外表面,碱基由于其一定程度的疏水性而位于双螺旋的内部。两条链上的碱基按A:T和G:C的互补规律相互以氢链连接,构成遗传信息可靠传递、DNA半保留复制的基础。两条主链并不充满双螺旋的空间,而在表面形成大沟和小沟。大沟是调控蛋白质识别DNA信息的主要场所。
DNA分子结构并非一成不变,而是在不同条件下可以有所不同,即DNA结构的多态性。在生理状态下DNA主要为B构象,并可能有少量的A构象和Z构象。Z构象是唯一存在的左手双螺旋构象。
DNA链上的四种碱基也非均匀分布,因而产生了一些特异的序列。回文序列是许多限制性核酸内切酶和调控蛋白的识别位点;富含A/T序列则是许多分子遗传学过程所不可缺少的;嘌呤和嘧啶的排列顺序对双螺旋的稳定性也有重大影响。
DNA在热或其他变性剂的作用下,双螺旋结构遭到破坏,双链发生分离,即变性。变性DNA的某些理化性质和生物学性质随之改变,如增色效应。核酸加热变性过程中紫外光吸收值达到最大值的50%时的温度称为核酸的解链温度(Tm),Tm值的大小与核酸分子大小和G+C所占总碱基数的百分比成正相关。变性的DNA单链在适当条件下又能恢复双螺旋结构,即复性作用。不同来源的变性核酸一起复性,则可能发生杂交,杂交是许多分子生物学技术的基础。
双螺旋DNA进一步扭曲而成的超螺旋称为DNA的三级结构。真核生物中,DNA与组蛋白形成核小体结构时,存在着负超螺旋。核小体是构成染色质的基本结构单位,每个核小体单位包括200bp左右的DNA和一个组蛋白八聚体以及一个分子的组蛋白H1。
RNA包括mRNA、hnRNA、rRNA、tRNA、snRNA和scRNA,它们均与遗传信息的表达有关。mRNA是遗传信息的携带者,其核苷酸序列决定着合成蛋白质的氨基酸序列;hnRNA是mRNA的前体,含有转录的、但不出现于成熟mRNA中的核苷酸片段(内含子);tRNA识别密码子,将正确的氨基酸转运至蛋白质合成位点;rRNA是蛋白质合成机器——核蛋白体的组成成分;snRNA在hnRNA向mRNA转变过程的剪接中起十分重要的作用。
复习题
1.比较RNA和DNA在结构上的异同点。
2.简述DNA双螺旋结构模式的要点及其与DNA生物学功能的关系。
3.原核生物与真核生物在基因组结构上有何不同?
4.什么是限制性片段长度多态性?
5.简述两种DNA序列测定方法的基本原理。
6.试述DNA结构的不均一性与其生物学功能的关系。
7.什么是核酸变性?简述影响特定核酸分子Tm的因素有哪些。
8.什么是分子杂交,何为探针?
9.试述RNA的种类及其生物学作用。

 中医世家
中医世家 浦 标 网
浦 标 网 河南大学精品课程
河南大学精品课程 图书资料室
图书资料室